Data Population¶
Prerequisites
- Access to a CDF Project.
- Know how to use a terminal, so you can run
pygenfrom the command line to generate the SDK. - Knowledge of your the data and data model.
Introduction to Problem¶
pygen can be used to ingest data into an existing data model. It is well suited when the source data is nested and comes in a format such as JSON.
Before you can ingest data you need the following:
- A Data Model Deployed to CDF.
- Generated an SDK for it.
In this guide, we will use some windmill data as an example. First, we already have a deployed a model and generated an SDK for it.
The model was generated with the follwing config from the pyproject.toml
[tool.pygen]
data_models = [
["sp_pygen_power", "WindTurbine", "1"],
]
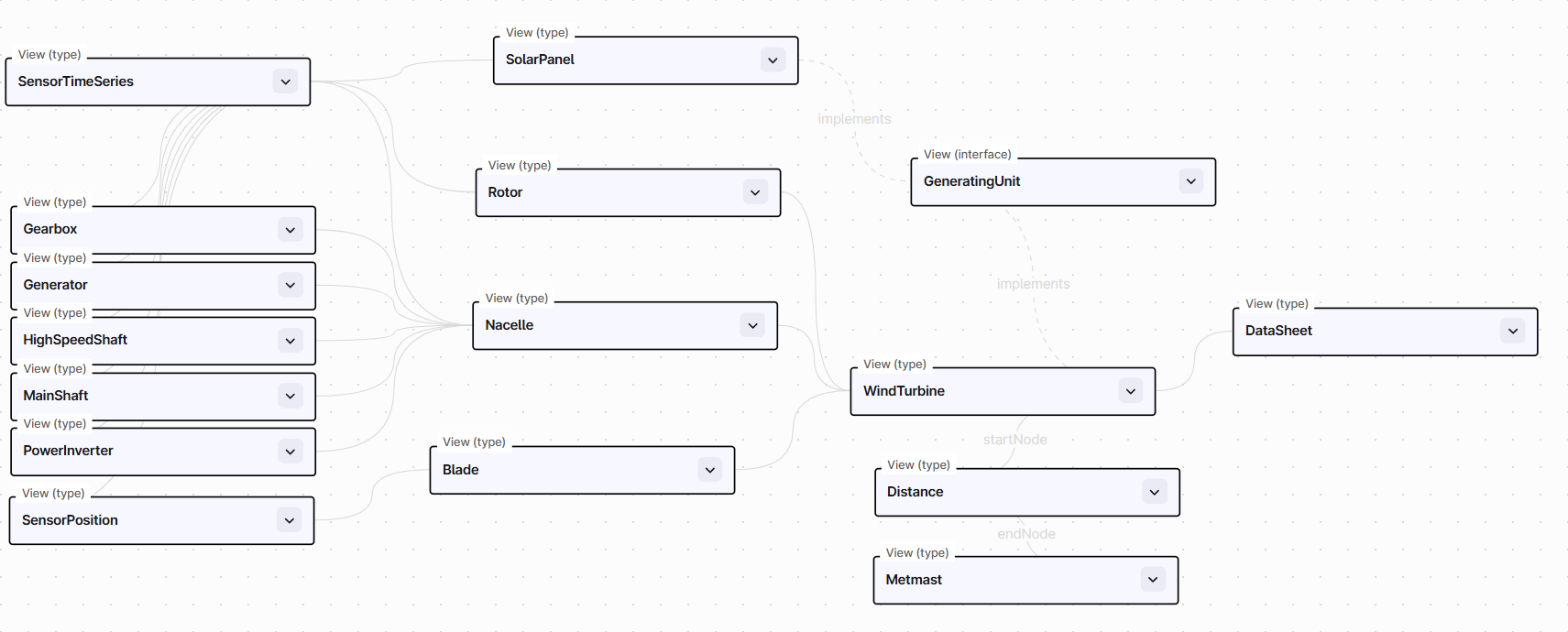
The model is illustrated in Cognite Data Fusions interface below:
First, we will inspect some of the data we have available
from tests.constants import JSON_DIR
source_filepath = JSON_DIR / "turbine.json"
print(source_filepath.read_text())
[{
"capacity": 7.0,
"name": "Doctrino Turbine 11",
"windfarm": "Oslo B2",
"blades": [
{
"is_damaged": false,
"name": "Blade A"
},
{
"is_damaged": false,
"name": "Blade B"
},
{
"is_damaged": true,
"name": "Blade C"
}
]
}]
As we see above, this is nested data, which is well suited for pygen supported ingestion
External ID Hook¶
All data in CDF data models needs to have an external_id set. Often, source data does not come with an external_id set, and to help this pygen comes with a built in hook that enables you to set external_id when you are ingesting the data. The name of this hook is an external_id_factory and you can set it importing the DomainModelWrite from your generated data classes.
from wind_turbine import data_classes as data_cls
from cognite.pygen.utils.external_id_factories import ExternalIdFactory
data_cls.DomainModelWrite.external_id_factory = ExternalIdFactory.create_external_id_factory()
The external_id_factory is a function that takes in two arguments, first a type which is the data class for the object and then a dict with the data for that partuclar object. pygen comes with a few generic external id factories you can use, see External ID factory These can be good for testing an exploration, but we recommend that you write your own factory function for (at least) the most important classes.
In the example below, we write a factory method that sets the ID for all windmills. Looking at the snippet below we note that the windmill have an name from the source system, so we would like to use this as the external_id.
from wind_turbine import data_classes as data_cls
fallback_factory = ExternalIdFactory.incremental_factory()
def my_factory(domain_cls: type, data: dict) -> str:
if domain_cls is data_cls.WindTurbineWrite:
return data["name"].replace(" ", "_")
else:
# Fallback to incremental
return fallback_factory(domain_cls, data)
# Finally, we set the new factory
data_cls.DomainModelWrite.external_id_factory = ExternalIdFactory.create_external_id_factory(
separator="-", suffix_ext_id_factory=my_factory
)
Ingesting the Data¶
After we have set the external_id_factory we are all good to go. pygen is generating pydantic data classes which means we can use the built in support for json validation in pydantic
We not that we had a list of wind turbines, in pydantic we use a TypeAdapter to parse a list of objects
from pydantic import TypeAdapter
turbines = TypeAdapter(list[data_cls.WindTurbineWrite]).validate_json(source_filepath.read_text())
# The WindmillWriteList has a few helper methods and nicer display than a regular list
turbines = data_cls.WindTurbineWriteList(turbines)
turbines
| space | external_id | capacity | name | blades | windfarm | data_record | |
|---|---|---|---|---|---|---|---|
| 0 | sp_wind | windturbine-Doctrino_Turbine_11 | 7.0 | Doctrino Turbine 11 | [{'space': 'sp_wind', 'external_id': 'blade-1'... | Oslo B2 | {'existing_version': None} |
We note that the external_id field is set to the name for the turbine. If we check the other objects we see these gets an external_id = class_name.lower()-counter
turbines[0].blades[0]
| value | |
|---|---|
| space | sp_wind |
| external_id | blade-1 |
| data_record | {'existing_version': None} |
| node_type | None |
| is_damaged | False |
| name | Blade A |
We can now upload this data by creating a domain client and call the pygen.upsert method.
from wind_turbine import WindTurbineClient
pygen = WindTurbineClient.from_toml("config.toml")
result = pygen.upsert(turbines)
print(f"{len(result.nodes)} nodes and {len(result.edges)} uploaded")
4 nodes and 0 uploaded
Note that pygen have the method .to_instances_write() you can use to check which nodesand edges were created.
We note that pygen created in total 4 nodes and 0 edges.
instances = turbines.to_instances_write()
len(instances.nodes), len(instances.edges)
(4, 0)
unique = set([source.source for node in instances.nodes for source in node.sources])
len(unique), unique
(2,
{ViewId(space='sp_pygen_power', external_id='Blade', version='1'),
ViewId(space='sp_pygen_power', external_id='WindTurbine', version='1')})
instances.nodes
| space | external_id | instance_type | sources | |
|---|---|---|---|---|
| 0 | sp_wind | windturbine-Doctrino_Turbine_11 | node | [{'properties': {'blades': [{'space': 'sp_wind... |
| 1 | sp_wind | blade-1 | node | [{'properties': {'is_damaged': False, 'name': ... |
| 2 | sp_wind | blade-2 | node | [{'properties': {'is_damaged': False, 'name': ... |
| 3 | sp_wind | blade-3 | node | [{'properties': {'is_damaged': True, 'name': '... |
instances.edges
# Cleanup
pygen.delete(turbines)
InstancesDeleteResult(nodes=[NodeId(space='sp_wind', external_id='windturbine-Doctrino_Turbine_11'), NodeId(space='sp_wind', external_id='blade-1'), NodeId(space='sp_wind', external_id='blade-2'), NodeId(space='sp_wind', external_id='blade-3')], edges=[])