Selecting / Querying¶
We assume that you have generated a SDK for the WindTurbine model and have a client ready to go.
Selecting/Querying is a different way of retrieving data than doing .list(), .retrieve(), search() in that it supports retrieving nested data structures, including filtering anywhere on the retrieved data structure. SDKs generated by pygen have two ways of selecting/querying which we will refer to as Python and GraphQL qurying. In this section, we will go through both of them,
and list limitations as well as when to use one over the other.
from wind_turbine import WindTurbineClient
pygen = WindTurbineClient.from_toml("config.toml")
Comparison¶
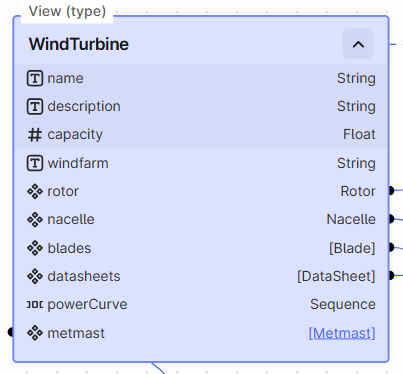
Python Based Querying/Selecting¶
Advantages
- Discovarability through the IDE through autocompletion.
- The returning data classes have required/optional set as in the data model, which are useful for static type checking and IDE auto complete.
- Regular filtering has same syntax as querying along any edge, direct relation, or reverse direct relation.
Limitations
- You can only query along one chain of connections. For example, if we start from
WindTurbineabove we can either go to blades or metmast, not both.
GraphQL Based Querying¶
Advantages
- Flexiblity in querying. You can retrieve anything you can write up as a graphql query.
Limitations
- Difficult to write the querying, typically you would use the CDF UI to create the query.
- The returning data class has all properties as optional and is thus less structured.
- Can become very verbose when you want to retrieve a lot of properties.
Summary¶
GraphQL based querying is more flexible, but gives you less structure on the returning data classes. In addition, the query will have to be created outside of your IDE which requires context switching.
Python Based Querying¶
Examples¶
Query: All turbines with nacelle:
result = pygen.wind_turbine.select().nacelle.list_full()
result
| space | external_id | capacity | name | blades | datasheets | nacelle | rotor | windfarm | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_3 | 7.0 | hornsea_1_mill_3 | [hornsea_1_mill_3_blade_A, hornsea_1_mill_3_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_3_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 1 | sp_wind | hornsea_1_mill_2 | 7.0 | hornsea_1_mill_2 | [hornsea_1_mill_2_blade_B, hornsea_1_mill_2_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_2_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 2 | sp_wind | hornsea_1_mill_1 | 7.0 | hornsea_1_mill_1 | [hornsea_1_mill_1_blade_A, hornsea_1_mill_1_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_1_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 3 | sp_wind | hornsea_1_mill_4 | 7.0 | hornsea_1_mill_4 | [hornsea_1_mill_4_blade_C, hornsea_1_mill_4_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_4_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 4 | sp_wind | hornsea_1_mill_5 | 7.0 | hornsea_1_mill_5 | [hornsea_1_mill_5_blade_B, hornsea_1_mill_5_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_5_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
Query: Get all blades for the windturbine named "hornsea_1_mill_1"
result = pygen.wind_turbine.select().name.equals("hornsea_1_mill_1").blades.list_blade()
result
| space | external_id | is_damaged | name | instanceType | data_record | |
|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_1_blade_A | True | A | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 1 | sp_wind | hornsea_1_mill_1_blade_B | False | B | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 2 | sp_wind | hornsea_1_mill_1_blade_C | False | C | node | {'version': 1, 'last_updated_time': 2024-11-16... |
Query: Get all blades for the windmill with external ID "hornsea_1_mill_3" or "hornsea_1_mill_4" with a damaged blade
result = (
pygen.wind_turbine.select()
.external_id.in_(["hornsea_1_mill_3", "hornsea_1_mill_4"])
.blades.is_damaged.equals(True)
.list_blade()
)
result
| space | external_id | is_damaged | name | instanceType | data_record | |
|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_4_blade_C | True | C | node | {'version': 1, 'last_updated_time': 2024-11-16... |
Same query as above but return the turbines
result = (
pygen.wind_turbine.select()
.external_id.in_(["hornsea_1_mill_3", "hornsea_1_mill_4"])
.blades.is_damaged.equals(True)
.list_full()
)
result
| space | external_id | capacity | name | blades | datasheets | nacelle | rotor | windfarm | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_4 | 7.0 | hornsea_1_mill_4 | [{'space': 'sp_wind', 'external_id': 'hornsea_... | [windmill_schematics] | hornsea_1_mill_4_nacelle | hornsea_1_mill_4_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
We can also inspect the query we are doing:
pygen.wind_turbine.select().nacelle
Query
Call .list_full() to return a list of Windturbine and .list_nacelle() to return a list of Nacelle.
In the query above, we go from WindTurbine node through the nacelle direct relation to the Nacelle node.
Autocomplete¶
Warning Notebook IDE
The autocomplete shown in the screenshots below works best in a jupyter notebook IDE. For example, VS Code notebook/PyCharm notebooks/Jupyter Lite (CDF Notebook) you might not get the same autocomplete when writing . + tab.
This style of querying is initiated by calling the .select() method on the place we want to start the query. Then, all properties that pygen supports filtering on are available as an attribute on the returning object of query. In addition, all types of connections (edges, direct relations, and reverse direct relations) can be traversed. Illustrated in the screenshot below. To get the list of possible options write . and press tab.
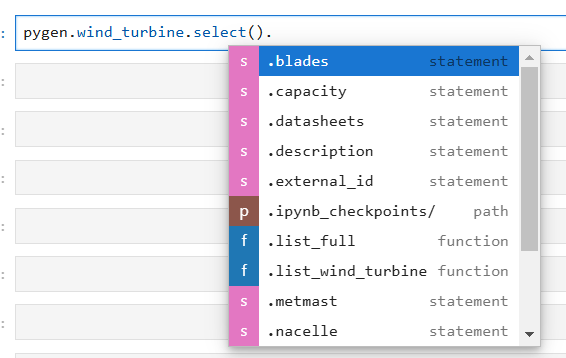
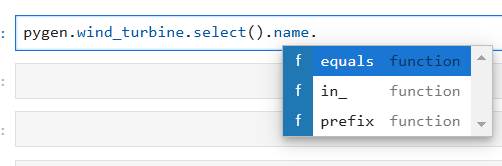
We can select a properties, and depending on the type of property, we will get the available filters up. For example, name is a string property which will make equals, in and prefix filter available.
Ones we have input the filterin values we are back at the source node and can continue to filter on properties of this node or traverse do the next one. In the example below, we traverse to the nacelle:
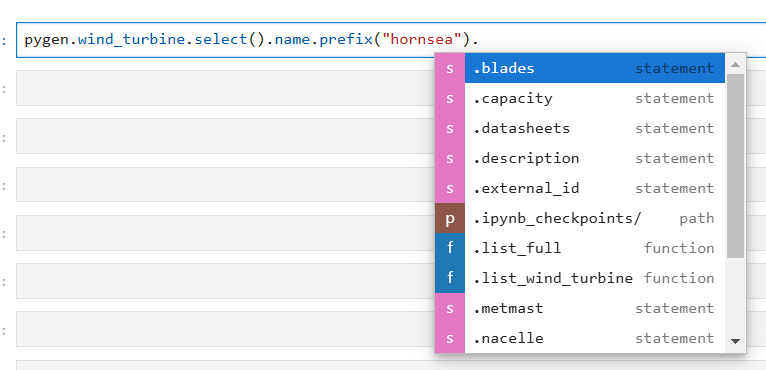
To make the query more readable it is recommended that you use the paranthesis syntax. This makes the query more readable.
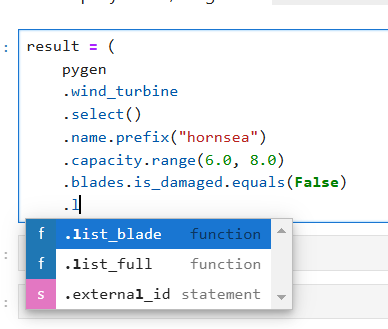
Finally, finish with either .list_full() or .list_<type>() to return the all nodes and edges in the query, or only the last node.
result = (
pygen.wind_turbine.select()
.capacity.range(6.0, 8.0)
.name.prefix("hornsea")
.blades.is_damaged.equals(True)
.list_blade()
)
result
| space | external_id | is_damaged | name | instanceType | data_record | |
|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_1_blade_A | True | A | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 1 | sp_wind | hornsea_1_mill_4_blade_C | True | C | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 2 | sp_wind | hornsea_1_mill_2_blade_B | True | B | node | {'version': 1, 'last_updated_time': 2024-11-16... |
Sorting¶
You can also sort the results returned by the .select() method. This is done by the .sort_ascending() and .sort_descending() property you are sorting.
Query: Get all damaged blades connected to turbines with capacity between 6.0 and 8.0 and a names that starts with "hornsea". Sort the blades by name
result = (
pygen.wind_turbine.select()
.capacity.range(6.0, 8.0)
.name.prefix("hornsea")
.blades.is_damaged.equals(True)
.name.sort_ascending()
.list_blade()
)
result
| space | external_id | is_damaged | name | instanceType | data_record | |
|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_1_blade_A | True | A | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 1 | sp_wind | hornsea_1_mill_2_blade_B | True | B | node | {'version': 1, 'last_updated_time': 2024-11-16... |
| 2 | sp_wind | hornsea_1_mill_4_blade_C | True | C | node | {'version': 1, 'last_updated_time': 2024-11-16... |
In addition, for properties of type TimeStampand Date you can use .latest() and .earliest(). This is a shorthand for calling .sort_descending()/.sort_decending() + setting limit=1.
Query: Get the latest uploaded datasheet for the "hornsea_1_mill_1" turbine
result = pygen.wind_turbine.select().name.equals("hornsea_1_mill_1").datasheets.uploaded_time.latest().list_data_sheet()
result
| space | external_id | is_uploaded | mime_type | name | uploaded_time | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | windmill_schematics | True | application/pdf | windmill_schematics.pdf | 2024-11-16 14:19:28.484000+00:00 | node | {'version': 2, 'last_updated_time': 2024-11-16... |
Direct Relations¶
We can both traverse and filter on connections that are modeled as a direct relations. pygen distinguish these by appending _filter to the attribute when filtering and nothing when traversing.
Query: Get all wind turbines with nacelles.
result = pygen.wind_turbine.select().nacelle.list_full(limit=5)
result
| space | external_id | capacity | name | blades | datasheets | nacelle | rotor | windfarm | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_3 | 7.0 | hornsea_1_mill_3 | [hornsea_1_mill_3_blade_A, hornsea_1_mill_3_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_3_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 1 | sp_wind | hornsea_1_mill_2 | 7.0 | hornsea_1_mill_2 | [hornsea_1_mill_2_blade_B, hornsea_1_mill_2_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_2_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 2 | sp_wind | hornsea_1_mill_1 | 7.0 | hornsea_1_mill_1 | [hornsea_1_mill_1_blade_A, hornsea_1_mill_1_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_1_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 3 | sp_wind | hornsea_1_mill_4 | 7.0 | hornsea_1_mill_4 | [hornsea_1_mill_4_blade_C, hornsea_1_mill_4_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_4_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
| 4 | sp_wind | hornsea_1_mill_5 | 7.0 | hornsea_1_mill_5 | [hornsea_1_mill_5_blade_B, hornsea_1_mill_5_bl... | [windmill_schematics] | {'space': 'sp_wind', 'external_id': 'hornsea_1... | hornsea_1_mill_5_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
result[0].nacelle
| value | |
|---|---|
| space | sp_wind |
| external_id | hornsea_1_mill_3_nacelle |
| data_record | {'version': 1, 'last_updated_time': 2024-11-16... |
| node_type | None |
| acc_from_back_side_x | V52-WindTurbine.Acc1N |
| acc_from_back_side_y | V52-WindTurbine.Acc2N |
| acc_from_back_side_z | V52-WindTurbine.Acc3N |
| gearbox | hornsea_1_mill_3_nacelle_gearbox |
| generator | hornsea_1_mill_3_nacelle_generator |
| high_speed_shaft | hornsea_1_mill_3_nacelle_highspeedshaft |
| main_shaft | hornsea_1_mill_3_nacelle_mainshaft |
| power_inverter | hornsea_1_mill_3_nacelle_powerinverter |
| wind_turbine | None |
| yaw_direction | V52-WindTurbine.yaw |
| yaw_error | V52-WindTurbine.YawErr |
| instanceType | node |
Query: Get the wind turibne with the nacelle hornsea_1_mill_3_nacelle
result = pygen.wind_turbine.select().nacelle_filter.equals("hornsea_1_mill_3_nacelle").list_full(limit=5)
result
| space | external_id | capacity | name | blades | datasheets | nacelle | rotor | windfarm | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | hornsea_1_mill_3 | 7.0 | hornsea_1_mill_3 | [hornsea_1_mill_3_blade_A, hornsea_1_mill_3_bl... | [windmill_schematics] | hornsea_1_mill_3_nacelle | hornsea_1_mill_3_rotor | Hornsea 1 | node | {'version': 19, 'last_updated_time': 2025-02-1... |
Max Selection Depth (Advanced)¶
When you call .select() pygen constructs a data structure that explores all path starting from the location you called select until a maximum depth is reached. If you try to select a path that is longer than this maximum you will get the following error.
try:
pygen.wind_turbine.select().nacelle.gearbox.displacement_x.list_sensor_time_series()
except ValueError as e:
print(e)
Max select depth reached. Cannot query deeper than 3. You can increase the max_select_depth in the global config. ``` from omni.config import global_config global_config.max_select_depth = 4 ```
As we see in the hint, we can increase this limit by setting the global_config.
Caveat: If you set this to a high value, the data structure pygen creates when calling .select() can become very large. It increases with the number of connections you have in the model, which means for a highly connected model the memory needed will increase exponentially with the depth you set. If you get a MemoryErrorException that is typically as a result of a too high max selection depth.
from wind_turbine.config import global_config
global_config.max_select_depth = 4
pygen.wind_turbine.select().nacelle.gearbox.displacement_x.list_sensor_time_series()
| space | external_id | aliases | concept_id | description | is_step | name | source_unit | standard_name | type_ | instanceType | data_record | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sp_wind | V52-WindTurbine.Gear_D_X | [Gearbox Displacement] | http://purl.org/aspect/gearbox_displacement | Gearbox Displacement X (laser sensor) (not cal... | False | Gear_D_X | V | gearbox_displacement | numeric | node | {'version': 1, 'last_updated_time': 2024-11-16... |
GraphQL based Querying¶
When querying with GraphQL we must include __typename of the top level items as this is used by pygen to understand how to pase the object.
The querying method is available on the top level client as this is not particular to any of the data types in your data model
my_query = """{
listWindTurbine(first:1){
items{
__typename
name
capacity
nacelle{
externalId
}
rotor{
externalId
}
blades{
items{
name
is_damaged
}
}
}
}
}"""
result = pygen.graphql_query(my_query)
result
| blades | capacity | nacelle | name | rotor | |
|---|---|---|---|---|---|
| 0 | [{'space': None, 'external_id': None, 'data_re... | 7.0 | {'space': None, 'external_id': 'hornsea_1_mill... | hornsea_1_mill_3 | {'space': None, 'external_id': 'hornsea_1_mill... |
result[0].model_dump(exclude_none=True)
{'blades': [{'is_damaged': False, 'name': 'A'},
{'is_damaged': False, 'name': 'B'},
{'is_damaged': False, 'name': 'C'}],
'capacity': 7.0,
'nacelle': {'external_id': 'hornsea_1_mill_3_nacelle'},
'name': 'hornsea_1_mill_3',
'rotor': {'external_id': 'hornsea_1_mill_3_rotor'}}
turbine = result[0]
turbine.nacelle.external_id
'hornsea_1_mill_3_nacelle'
Pitfalls¶
If you forget to include __typename on the top level item pygen will raise a Runtime error
my_invalid_query = """
{
listWindTurbine(first:1){
items{
name
}
}
}
"""
try:
pygen.graphql_query(my_invalid_query)
except RuntimeError as e:
print(e)
Missing '__typename' in GraphQL response. Cannot determine the type of the response.
Data Classes¶
When you call .list(), .retrieve() and .search(), pygen returns ther read format of data classes. This read format matches the type/view required/optional properties.
When you do the graphql_query above all properties are optional as pygen cannot know which objects you included in your query, thus pygen uses a special GraphQL format of the
data class it is returning
my_query = """{
listWindTurbine(first:1){
items{
name
__typename
}
}
}"""
result = pygen.graphql_query(my_query)
type(result)
wind_turbine.data_classes._core.base.GraphQLList
type(result[0])
wind_turbine.data_classes._wind_turbine.WindTurbineGraphQL
This data class can be converted to a regular write or read format by calling the as_write and as_read call.
Warning If you have not included all required properties in the your GraphQL query, pygen will raise an ValueError when you do this call.
try:
result[0].as_read()
except ValueError as e:
print(e)
2 validation errors for WindTurbine
externalId
Field required [type=missing, input_value={'name': 'hornsea_1_mill_3'}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.9/v/missing
data_record
Field required [type=missing, input_value={'name': 'hornsea_1_mill_3'}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.9/v/missing
my_query = """{
listWindTurbine(first:1){
items{
name
space
externalId
createdTime
lastUpdatedTime
__typename
}
}
}"""
result = pygen.graphql_query(my_query)
windmill_read = result[0].as_read()
windmill_read
| value | |
|---|---|
| space | sp_wind |
| external_id | hornsea_1_mill_3 |
| data_record | {'version': 0, 'last_updated_time': 2024-12-17... |
| node_type | None |
| capacity | None |
| description | None |
| name | hornsea_1_mill_3 |
| blades | None |
| datasheets | None |
| metmast | None |
| nacelle | None |
| power_curve | None |
| rotor | None |
| windfarm | None |
type(windmill_read)
wind_turbine.data_classes._wind_turbine.WindTurbine
windmill_write = result[0].as_write()
windmill_write
| value | |
|---|---|
| space | sp_wind |
| external_id | hornsea_1_mill_3 |
| data_record | {'existing_version': 0} |
| node_type | None |
| capacity | None |
| description | None |
| name | hornsea_1_mill_3 |
| blades | None |
| datasheets | None |
| metmast | None |
| nacelle | None |
| power_curve | None |
| rotor | None |
| windfarm | None |
type(windmill_write)
wind_turbine.data_classes._wind_turbine.WindTurbineWrite
Paging¶
If we include a pageInfo in our query this will be available directly on the result returned from the .graphql_query method
my_query = """
{
listWindTurbine{
items{
__typename
name
}
pageInfo{
hasNextPage
hasPreviousPage
startCursor
endCursor
}
}
}"""
result = pygen.graphql_query(my_query)
result.page_info.has_next_page
True
result.page_info.end_cursor
'Z0FBQUFBQm5jcVdlTGd2ZmRFdVNrLW1PUnFvaEl0RV8xaGU4cU95d2o1SWFQdWxFZVVyeTZ4OEhKR09kNjIzMTh4b1BYU09jZHI1bkhRN05rMDkzUWhubnFkRVhVNjB0bUZkd0JFQ3BzS0l6ZVBuRUdIQXRGX0tza2tTVVhlWkV6cUMxVGdyX2t1aEk4S1Bvd0Y0aVJnUDk0NU41d2M1R3pFV2ZnelpOS1J6RDkxTWRiUTY2SHB2Y0ZEc05MVElLbk9WQjNaUERtaE1DRlY4akhWSmhZWmJHZzhVaEFLdm5rQjFHbU9vNFRFQm5BUG90ZXNlNHhPQm5HUEZzajJZSmhJNjFpVFYzcEpkVQ=='
Datapoints¶
You can use the getDatapoints to include datapoints for a referenced timeseries.
my_query = """{
listMetmast(first: 1){
items{
__typename
temperature{
externalId
name
getDataPoints(granularity: "1d", aggregates: SUM, first: 100){
items{
timestamp
sum
}
}
}
}
}
}"""
result = pygen.graphql_query(my_query)
metmast = result[0]
metmast.temperature.data.to_pandas()
| utsira_station_temperature|sum | |
|---|---|
| 2020-12-31 | -9.844667 |
| 2021-01-01 | -254.494219 |
| 2021-01-02 | -495.438664 |
| 2021-01-03 | -588.549775 |
| 2021-01-04 | -602.327553 |
| ... | ... |
| 2021-04-05 | 87.561336 |
| 2021-04-06 | 235.783558 |
| 2021-04-07 | 295.394670 |
| 2021-04-08 | 167.116892 |
| 2021-04-09 | -0.383108 |
100 rows × 1 columns
You can use the getLatestDataPoint to include the latest datapoint for a referenced timeseries.
my_query = """{
listMetmast(first: 1){
items{
__typename
temperature{
externalId
name
getLatestDataPoint{
items{
timestamp
value
}
}
}
}
}
}"""
result = pygen.graphql_query(my_query)
metmast = result[0]
metmast.temperature.latest
| value | |
|---|---|
| 2024-12-30 13:00:00 | -0.122444 |
Next section: Creating and Deleting